Continuous integration and continuous deployment (CI/CD) is a practice that enables an organization to rapidly iterate on software changes while maintaining stability, performance and security.
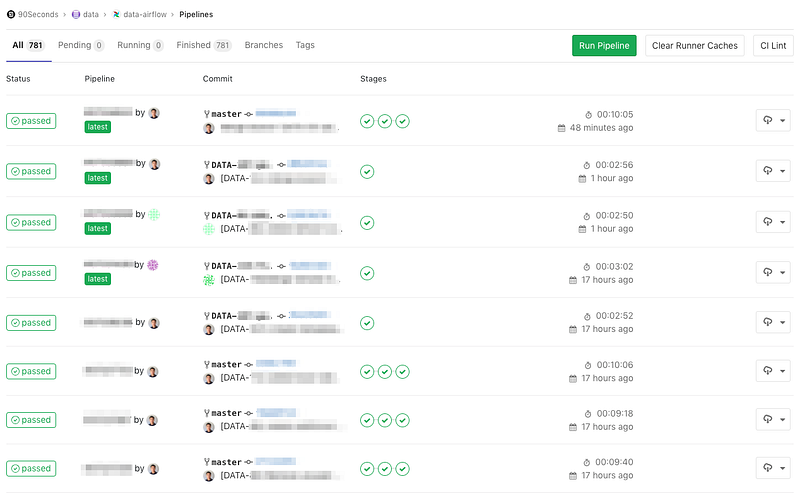
Although continuous integration and deployment (CI/CD) are not new concepts, new tools such as Docker, Kubernetes, and Jenkins have allowed CI/CD to be more easily implemented in recent years. However, there are interesting challenges when applying CI/CD to data engineering.
Challenges with CI/CD in Data
Replication of environments

In modern software engineering workflows, there are usually development, staging and production environments. In software engineering, development and staging databases usually mimic a fraction of the production database. This assumes that the differences in data would not matter. In software engineering, this is usually the case.
In data engineering, we are unable to create a staging environment for some 3rd party data sources. Yet, our development and staging environments should try to mimic our production environment to ensure consistency in environments. But replicating data environments can be difficult, depending on the size of your data and existing infrastructure.
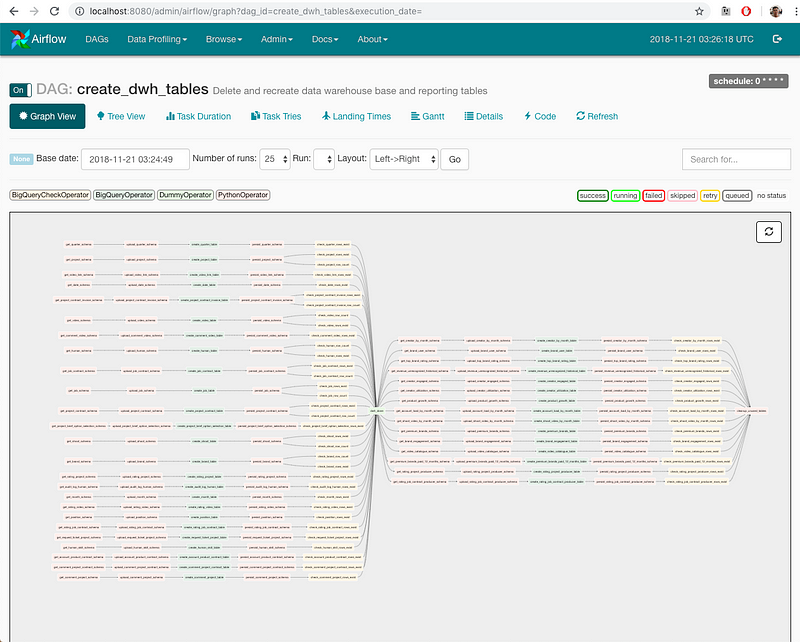
Tests take too long
Tests are designed to give quick feedback in CI/CD, ensuring as many iterations as possible so that bugs can be caught and fixed quickly. However, testing data pipelines might require testing queries that take more time than an average integration test.
Legacy
Existing data pipelines might have been in place before CI/CD was even considered. This makes things complicated because a lot of code would need to be redesigned to consider different environments. Other than technical legacy, it might also come in the form of organisational legacy where people are not used to having multiple environments. Educating different stakeholders and engineering teams to get used to a CI/CD workflow would not be easy. Besides, it would also require significant changes in processes.
A typical data architecture
Instead of hypothetical examples, let’s take a look at a simplified data architecture which follows the ELT principle. For this example, we will be using Google Cloud Platform, which is similar to other cloud providers.
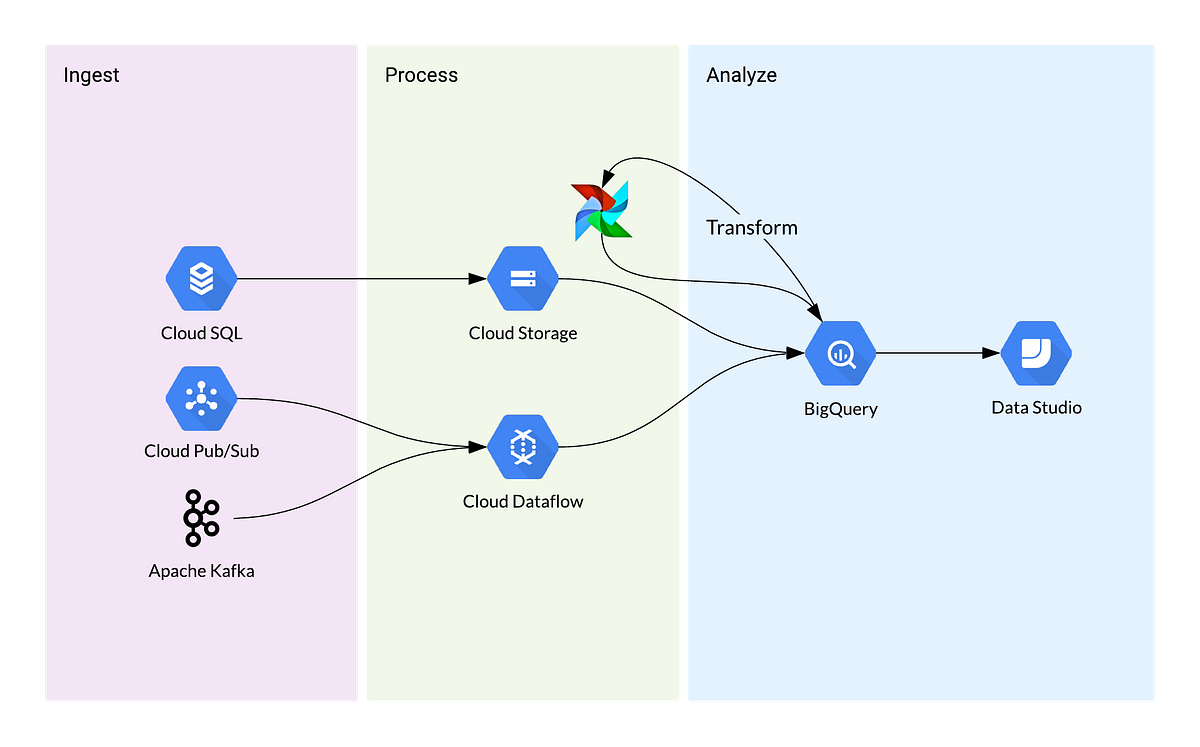
Looking at this architecture, we notice some challenges if we were to fully adopt the modern development workflow. For one, it’d be impossible to create a BigQuery instance for each data engineer on their development environment since this is likely a local setup. And if you were to create one BigQuery instance on the cloud for each engineer, it will likely be too costly.
Say you wanted to test your pipeline. How would you go about doing an integration test? With any modern application, there’s usually a library for that but how do you verify the data integrity in development and pinpoint the source of the error without a complete copy of the production environment?
If you had thought about these issues, you’d be surprised that some companies had never thought of it. Some teams might not be experienced or have an engineering mindset. So they started building things from the get-go, without considering how best to control technical debt. Once enough things are built and the process is settled, it’ll be difficult to make any significant changes.
Some of these issues convince some companies to simply go with one environment — production. But there can be a compromise and I’d argue that multiple environments encourage higher code quality and data integrity.
A better workflow
Since we are unable to strictly adopt a software development workflow, we will have to make some compromises.
Instead of having a dedicated BigQuery instance to each data engineer for the development environment, we will have a shared one. For this to work, all tables have to be easily torn down and rebuilt — following a functional approach to data engineering. The BigQuery API integration with Airflow also helps us with that.
With every merge request, a series of automated tests will be run. BigQuery gives us some cool API calls to check the validity and cost of our queries which helps us with testing. Though not a strict unit test, it gives us quick feedback from automated testing so we could catch errors before they are pushed to production.
A shared BigQuery instance in development and test environments will inevitably result in unexpected errors, especially when the state of the shared BigQuery instance is dependent on the last executed Airflow DAG. But since we have followed a functional approach to data engineering, resetting the state of the data warehouse is quick and easy.
Applying CI/CD as best as we can gives us a nice workflow to test our pipelines and logic before pushing them to production.
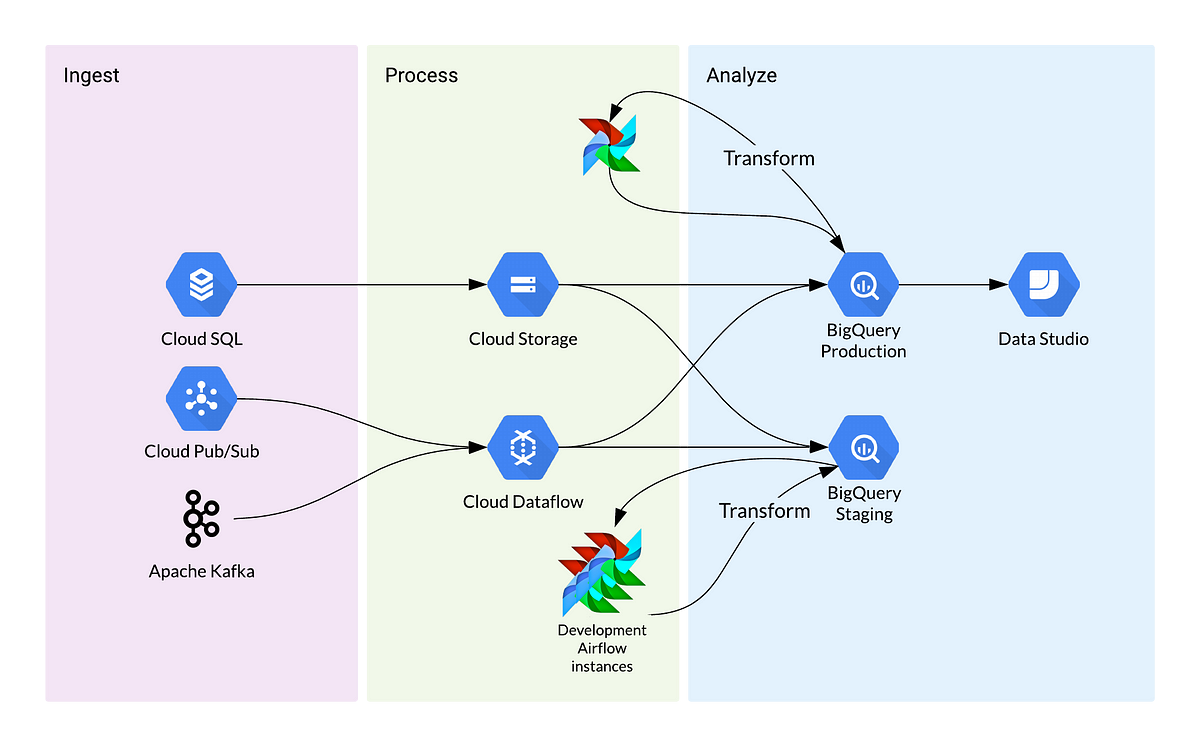
Though this is similar to our current setup at 90 Seconds, every company has a different data architecture and constraints. I’d expect our setup to evolve as data needs change and better tools are being developed.
Data Engineers need to think like Software Engineers
In a lot of ways, data engineers are software engineers, though with different constraints. Concepts such as functional programming, containerization and TDD might not be applicable all the time but it’s a good place to start. Let’s start with first principles and maybe, just maybe, there’ll be a new set of conventions created by the data engineers built upon the shoulders of software engineering.